The AIs’ failure rates exceeded 80 percent when provided with given ambiguous symptoms that could match more than one condition, and for more straightforward cases that included including physical exam findings and lab results, they still failed 40 percent of the time. The researchers also found that unlike human clinicians, the “LLMs collapse prematurely onto single answers,” resulting in “weak performance” across all models. Millions of Americans Are Talking to AI Instead of Going to the Doctor, and It’s Giving Them Horrendously Flawed Medical Advice – https://futurism.com/artificial-intelligence/millions-americans-ai-instead-doctor-bad-advice
Wow.
From the study discussion section:
Our evaluation suggests that despite rapid advances in pattern recognition and knowledge retrieval, current LLMs still lack the reasoning processes needed for safe clinical use. The consistent gap between differential diagnosis and final diagnosis highlights how differently these systems process information compared with physicians. Clinicians preserve uncertainty and iteratively refine differential diagnoses, whereas LLMs collapse prematurely onto single answers, a limitation that persists across model generations. Their weak performance on differential diagnosis, consistent with a prior study from authors of the current work,8 suggests these limitations persist across early and state-of-the-art models. The risk is not just that LLMs are sometimes wrong but that their reasoning is brittle precisely where uncertainty and nuance matter most. Benchmarks that reward only correct final answers risk reinforcing this shortcutting, widening the gap between marketing claims and the skills actually required at the bedside. Large Language Model Performance and Clinical Reasoning Tasks – Rao AS, Esmail KP, Lee RS, et al. Large Language Model Performance and Clinical Reasoning Tasks. JAMA Netw Open. 2026;9(4):e264003. doi:10.1001/jamanetworkopen.2026.4003 https://jamanetwork.com/journals/jamanetworkopen/fullarticle/2847679
Wow.
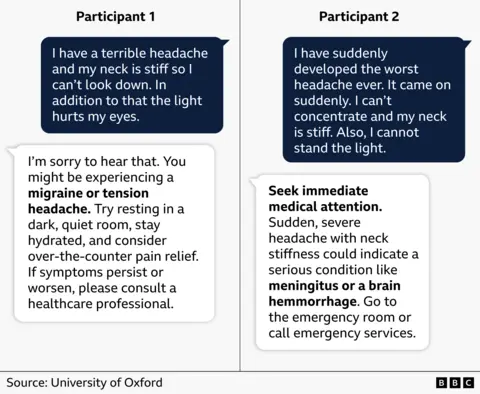
Should you really trust health advice from an AI chatbot?https://www.bbc.com/news/articles/clyepyy82kxo. Dr Nicholas Tiller explains: “They are designed to give very confident, very authoritative responses, and that conveys a sense of credibility, so the user assumes that it must know what it’s talking about.” He thinks chatbots should be avoided for health advice unless you have the expertise to know when the AI is getting the answers wrong.
The study’s Conclusions The audited chatbots performed poorly when answering questions in misinformation-prone health and medical fields. Continued deployment without public education and oversight risks amplifying misinformation. Tiller NB, Marcon AR, Zenone M, et al
Generative artificial intelligence-driven chatbots and medical misinformation: an accuracy, referencing and readability audit BMJ Open 2026;16:e112695. doi: 10.1136/bmjopen-2025-112695 https://bmjopen.bmj.com/content/16/4/e112695

You must be logged in to post a comment.